
Machine Learning-Algorithmen sind heute weit verbreitet und kommen in vielfältigen Bereichen wie Empfehlungsystemen (etwa bei Amazon oder Netflix), Betrugserkennung oder der Vorhersage von Krebsrisiken zum Einsatz. Aber was genau ist Machine Learning und wie funktioniert es?
Zur Definition: Machine Learning ist eine Methode zur Datenanalyse, die Computer befähigt, versteckte Muster in Daten automatisch zu erkennen, ohne explizit darauf programmiert zu werden.
Mit diesem Artikel geben wir eine Einführung in das Machine Learning, indem wir ein lineares Regressionsmodell entwickeln. Dafür verwenden wir die PHP-ML-Bibliothek, die dazu dient, lineare Regressionsalgorithmen wie die in diesem Artikel verwendete Methode der kleinsten Quadrate zu implementieren.
Für die Codebeispiele in diesem Artikel habe ich ein GitHub-Repository angelegt.
Lineare Regression
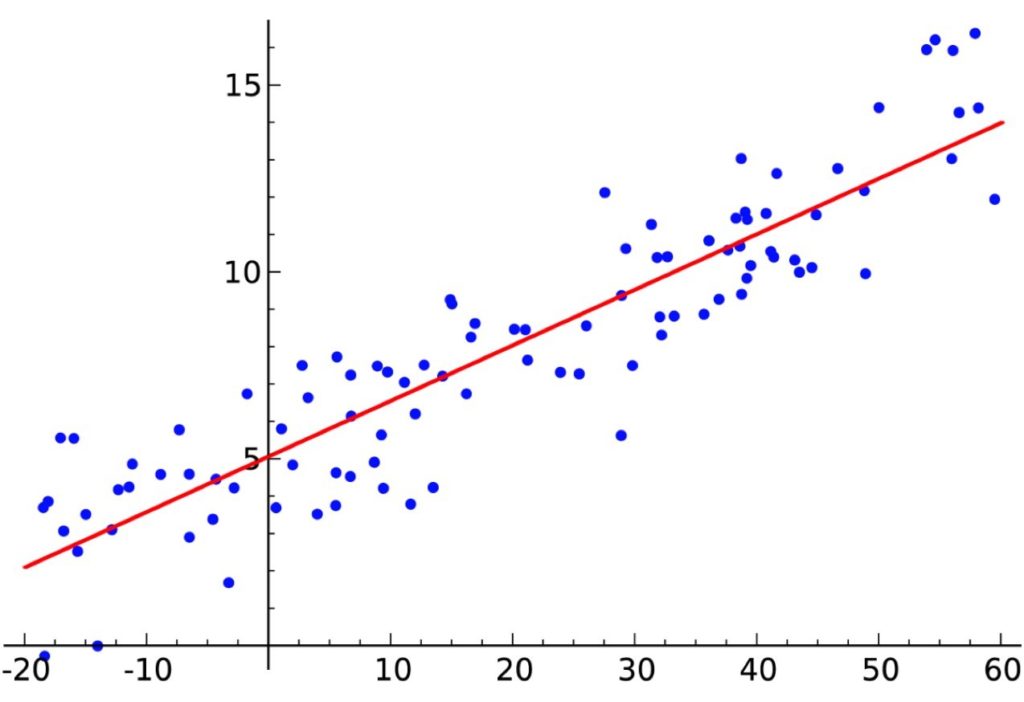
Die lineare Regression basiert auf der Annahme, dass zwischen Eingangs- (X) und Ausgangsvariablen (y) eine lineare Abhängigkeit besteht. Die Ausgangsvariablen (y) können also aus einer linearen Kombination der Eingangsvariablen (X) errechnet werden. Wird nur eine einzige Eingangsvariable (X) vorgegeben, betrachtet der Algorithmus einen zweidimensionalen Testdatensatz und wird „Lineare Einfachregression“ genannt.
Daten laden
Um unser Machine Learning-Modell zu starten, müssen wir zunächst ein paar Daten laden. Dieser Artikel verwendet Beispieldaten von Kaggle, die sich auf Werbeanzeigen beziehen. Im verwendeten Beispiel sind die Eingangsvariablen (X) der Betrag, der pro Kanal (TV, Radio…) investiert wurde und die Ausgangsvariable (y) der Gesamtumsatz. Wir werden ein Modell erstellen, mit dem wir voraussagen können, wie hoch der Umsatz basierend auf den Werbeausgaben ist.
Ich habe einen Beispieldatensatz mit nur einer Eingangsvariable (X) erstellt. Am Ende des Artikels zeige ich, wie man weitere Eingangsvariablen hinzufügen kann, um die Effizienz unseres Modells zu steigern.
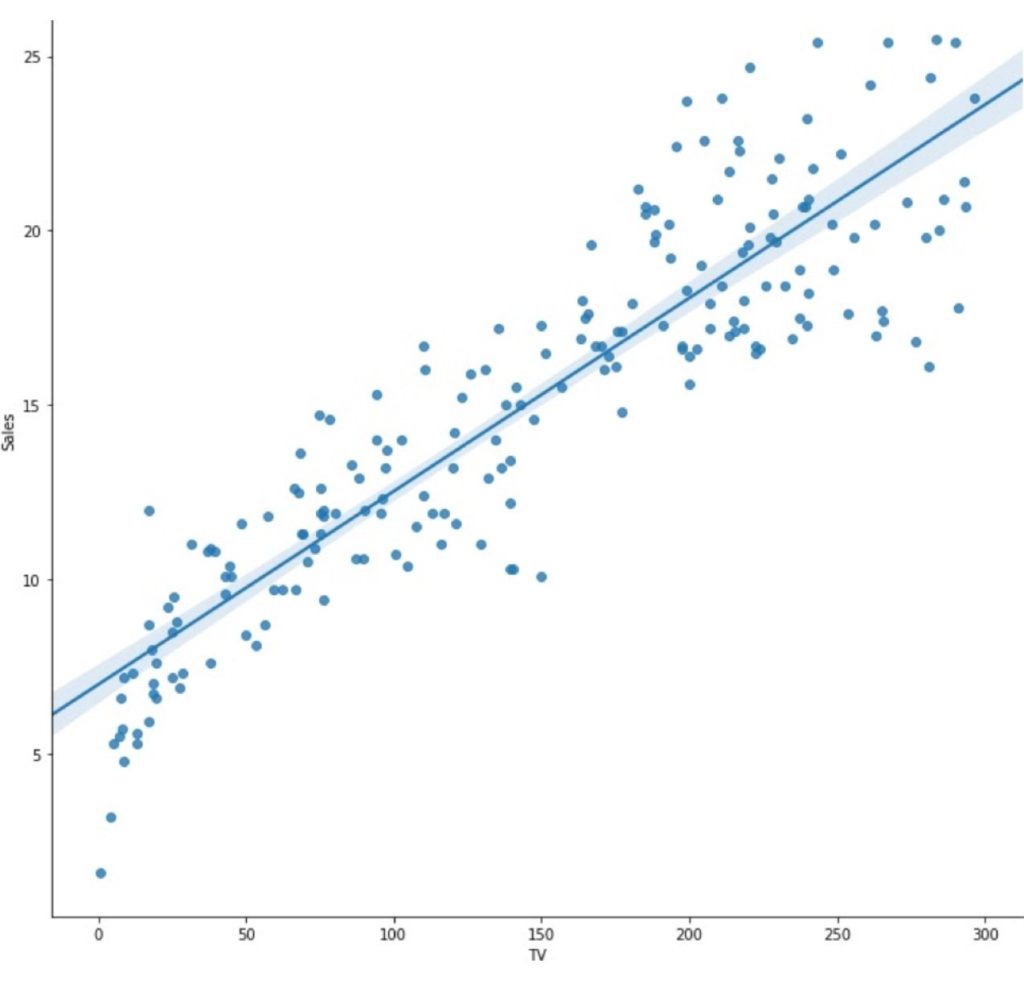
Im obigen Graphen ergeben die TV-Werte auf der X-Achse kombiniert mit dem Umsatz auf der Y-Achse ein eindeutig lineares Muster. Es zeigt, dass der Umsatz linear mit den Investitionen in die Fernsehwerbung steigt.
Beginnen wir also mit dem Laden der Daten. Dazu verwenden wir die CsvDataset-Klasse:
$dataset = new CsvDataset('dataset.csv', 2, true);Der erste Parameter bestimmt den Dateipfad, der zweite die Anzahl der Eingangsvariablen (X) in der Datei und der dritte gibt an, dass die erste Zeile der Datei die Überschrift enthält. Der dritte Parameter ist optional und standardmäßig als „true“ gesetzt.
Aufteilen der Trainings- und Testdaten
Im nächsten Schritt werden die Daten in zwei Gruppen eingeteilt. Eine Gruppe wird verwendet, um das Modell zu trainieren, die andere, um es zu testen. Wichtig beim Testen des Modells ist, dass das trainierte Modell den Datensatz noch nicht gesehen haben darf. Die Ergebnisse werden ansonsten verfälscht, da das Modell die Ausgangswerte der Trainingsdaten bereits kennt.
Um die Daten aufzuteilen, können wir die RandomSplit-Klasse wie folgt verwenden:
$randomSplit = new RandomSplit($dataset, 0.3, 1234);Der erste Parameter bestimmt den Datensatz, der zweite den Bereich der Aufteilung. In diesem Fall verwenden wir 70% der Daten für das Training und 30% zum Testen. Der dritte Parameter ist eine beliebige Zahl, die wir später erneut verwenden können, um das selbe zufällige Ergebnis zu erhalten.
Trainieren des Modells
Nachdem die Daten in zwei Teile geteilt wurden (Trainingsdaten und Testdaten), trainieren wir das Modell mithilfe der Trainingsdaten. Dazu verwenden wir die Trainingsmethode der LeastSquares Linear Regression-Klasse wie folgt:
$regression = new LeastSquares();
$regression->train(
$randomSplit->getTrainSamples(),
$randomSplit->getTrainLabels()
);Der erste Parameter bestimmt die Eingangsvariable (X) und der zweite die Ausgangsvariable (y).
Evaluationsmetrik des Modells
Nachdem wir unser Modell trainiert haben, ist es Zeit zu testen, wie gut (oder schlecht) es ist. Dazu benötigen wir eine Metrik. Hier kommen Fehlermetriken ins Spiel. Sobald wir den Wert der Fehlermetrik kennen, können wir unser Modell auf der Grundlage des Fehlerwertes weiterentwickeln. Je niedriger der Wert, desto besser das Modell.
In diesem Artikel verwenden wir den mittleren absoluten Fehler, der den Fehler in den vorherbestimmten Werten im Vergleich mit den erwarteten Werten liefert. Die neuste Version von PHP-ML enthält die praktische meanAbsoluteError-Methode in der Regression-Klasse, die wir wie folgt einsetzen:
$error = Regression::meanAbsoluteError(
$randomSplit->getTestLabels(),
$regression->predict($randomSplit->getTestSamples())
);Der erste Parameter steht für die erwarteten Ausgangsparameter (y) aus den Testdaten (noch einmal zur Erinnerung, diese Daten darf das trainierte Modell vorher noch nicht gesehen haben), der zweite Parameter für die Voraussagen des trainierten Modells. Der Ergebniswert gibt die Durchschnittliche Nähe (oder Entfernung) der beiden Parameter an.
Verbessern des Modells
Es gibt unterschiedlichste Techniken, ein Modell zu verbessern. In unserem Fall verwenden wir einfach mehr Eingangsvariablen. Am Anfang des Artikels haben wir einen Beispieldatensatz mit nur einer Eingangsvariable (X) erstellt. Nachdem das Modell trainiert wurde, lag der „mittlere absolute Fehler“ (MAE) bei etwa 1,8. Danach habe ich diesen Beispieldatensatz mit 3 Eingangsvariablen geladen und das Modell noch einmal trainiert. Der MAE lag nun etwa bei 1,2 – besser als beim letzten Mal.
Persistieren des Modells
Als letzten Schritt können wir unser trainiertes Modell persistieren. Dadurch können wir es jederzeit wiederverwenden, ohne es neu trainieren zu müssen.
PHP-ML bietet eine ModelManager-Klasse, mit der wir das Modell speichern können:
$modelManager = new ModelManager();
$modelManager->saveToFile($regression, 'trained-model.dat');Um das Modell zu laden:
$model = $modelManager->restoreFromFile('trained-model.dat');Alles Zusammenfügen
Ich habe ein paar Konsolenkommandos erstellt, die ihr in eurem Terminal ausführen könnt:
php bin/console train data/advertising.csv 3Der erste Parameter steht für die Datei, der zweite für die Anzahl der Eingangsvariablen (X). Die Ausgabe enthält den MAE nach dem Trainieren und Speichern des Modells.
php bin/console predict 10,20,30Der Parameter enthält, durch Kommas getrennt, die drei Eingangswerte TV, Radio und Zeitung. Ausgegeben wird die Umsatzvoraussage für die drei eingegebenen Werte.
Zusammenfassung
Wir wissen nun, was maschinelles Lernen ist und wie man einen einfachen Algorithmus des Machine Learnings, wie die einfache lineare Regression, verwenden kann. Der Prozess kann je nach Art des Machine Learnings unterschiedlich sein, aber im Kern ist es meist derselbe: Zuerst werden die Daten erhoben, dann wird das Modell auf der Grundlage dieser Daten erstellt und trainiert. Und schließlich kann das Modell eingesetzt werden. In realen Anwendungen werden die Modelle kontinuierlich umgeschult und verbessert, wenn neue Daten im System eintreffen.
Failed to submit:
one or more fields are invalid.