
Erinnerst du dich an den letzten Frühjahrsputz in deinem CMS? Falls nicht, bist du in bester Gesellschaft. Die meisten Corporate-Sites wirken wie Dachböden voller unbeschrifteter Kisten: Whitepaper-PDFs, die niemand mehr öffnet, Blog-Einträge ohne einheitliche Taxonomie, verwaiste Pressemitteilungen aus der “Vor-GDPR-Ära”. Für menschliche Nutzerinnen ist das schon nervig, für Large Language Models ist es pures Fast-Food ohne Nährwert. Google erklärt inzwischen ganz offen, dass strukturierte Daten unverzichtbar sind, um Inhalte in seinen Knowledge-Graph einzuordnen und sie überhaupt erst als zitierfähige Quelle zu listen. Analystinnen haben nachgewiesen, dass genau diese strukturierte Kost die Fehlerquote generativer Antworten halbiert. Wenn wir unser digitales Inventar also weiter als lose Pixelansammlung behandeln, riskieren wir, dass Chatbots unser teuer produziertes Know-how entweder übersehen oder schlimmer noch falsch zusammensetzen. Dabei geht es gar nicht um mehr Content, sondern um bessere Statik. Ohne saubere Sitemaps, solide Canonicals, eindeutige Slugs und JSON-LD-Blöcke wird selbst der brillanteste Fachartikel zum Zombie im Index. Die pragmatische Konsequenz lautet: Bevor du die nächste Kampagne startest, inventarisiere erst dein Altmaterial und verankere es so fest in der Informationsarchitektur, dass Maschinen genau wie Menschen wissen, welches Regal sie ansteuern müssen. Dann landet deine Expertise nicht als digitales Staubkorn in irgendeiner Vektormatrix, sondern als zitierbarer Knoten im Wissensnetz der Zukunft.
Struktur schlägt Menge: Knowledge Graphs als Vitaminbooster für LLMs
Sprache ist chaotisch, Maschinen lieben Ordnung. Deshalb verweben immer mehr Unternehmen Large Language Models mit internen Knowledge Graphs oder Small Language Models, die hochspezialisierte Dateninseln abdecken. Studien zeigen, dass Gemini und Co. Antworten ausdrücklich mit strukturierten Schemas anreichern. Wer heute Produktseiten ohne Product-Schema oder Jobangebote ohne JobPosting-Markup veröffentlicht, liefert den Modellen leere Kalorien. Für Enterprise-CMOs bedeutet das: Daten aus PIM-, CRM- oder DAM-Systemen müssen nicht nur vollständig, sondern semantisch präzise und maschinenlesbar sein. In WordPress gelingt das wahlweise via WPGraphQL, ACF-to-REST oder Yoast, die Rohdaten als JSON-LD injizieren und Headless-Endpunkte sofort bespielbar machen. So entsteht ein Datenlayer, den Agenten per Retrieval-Augmented Generation abfragen können, ohne sich durch Freitext zu wühlen. Je klarer du jede Entität – Stichwort Produkt-ID, Autor-Profil, Standort-Code – kennzeichnest, desto seltener musst du später Prompt-Gymnastik betreiben, weil das Modell bereits weiß, wo die Wahrheit liegt. Ein positiver Nebeneffekt: Konsistente Entitäten sorgen auch intern für weniger Doubletten und vereinfachen Reportings Richtung Vorstandsetage.
SEO im Agentic Zeitalter: Von Rankings zu Recall Signalen
Deloitte prognostiziert, dass 2025 schon ein Viertel aller Gen-AI-Teams Agentic-Piloten laufen lassen und 2027 jedes zweite Unternehmen autonome Workflows einführen will. Sobald solche Agenten selbstständig Kaufentscheidungen treffen, hängen ihre Aktionen an Datengerüsten – nicht an bunten Landingpages. Klassische SEO-Metriken wie Pagespeed und interne Verlinkung bleiben unverzichtbar, weil sie Maschinen dabei helfen, Vertrauen zu quantifizieren. Der entscheidende Unterschied: Früher reichte ein Platz in den Top-Drei der organischen Treffer für Sichtbarkeit. Heute garantiert dir nur sauber gesetztes Schema die Aufnahme in den Langzeitspeicher eines Modells. Sichtbarkeit verwandelt sich in Memorierbarkeit. Für Content-Teams heißt das: Jeder Absatz braucht ab sofort einen semantischen Zwilling, jede Grafik ein beschreibendes Entity-Tag. An die Stelle von Keyword-Stuffing treten Konsistenz-Regeln: Gleiches Produkt, gleiche SKU, gleiche Preise über alle Kanäle hinweg. Nur so verhinderst du, dass Agenten widersprüchliche Informationen halluzinieren und deine Marke bei der nächsten Anfrage aus dem Speicher kegeln. Wer diese Regeln ignoriert, riskiert, dass ein autonomer Beschaffungs-Bot beim Wettbewerb kauft, weil dort der Datensatz sauberer war.
Vom Content Chaos zum skalierbaren Datenlayer: Der Fahrplan
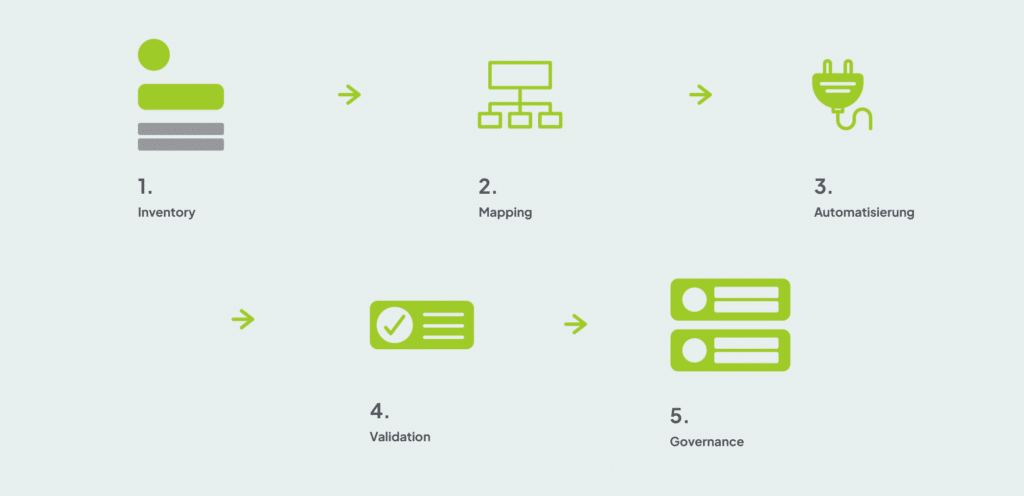
Wie gelingt die Metamorphose praktisch?
- Schritt eins: Inventory. Erstelle eine vollständige Liste aller Content-Quellen – von WordPress-Posts über PDF-Archive und Media-Library bis zur Produktdatenbank.
- Schritt zwei: Mapping. Ordne jeder Quelle ein geeignetes Schema-Vocabulary zu. Google empfiehlt sogar eigens definierte PageMaps, wenn Standardtypen nicht reichen.
- Schritt drei: Automatisierung. Implementiere Middleware oder WordPress-Plugins, die bei jedem Publishing-Event Schema-Daten injizieren.
- Schritt vier: Validation. Nutze den Rich-Result-Test nicht nur für Fehlermeldungen, sondern für Logiklücken und Abweichungen zwischen Frontend und Quellsystem.
- Schritt fünf: Governance. Weise jeder Datendomäne einen Owner zu und plane halbjährliche Audits, damit der neue Layer nicht wieder zum Datenfriedhof mutiert.
Branchenexperten erinnern daran, dass strukturierte Daten zwar kein direkter Ranking-Faktor sind, generative Modelle ohne sie aber deutlich an Präzision verlieren. In der Praxis sehe ich Budgets inzwischen dorthin wandern, wo sie echten Impact liefern: in semantische Pipelines, GraphQL-Gateways und Monitoring für Schema-Fehler. Unternehmen, die heute investieren, bauen eine Informations-Lieferkette, die sowohl Screenreadern als auch Agentic-Systemen schmeckt.
KPI Radar und Governance: So misst du den Erfolg deines Daten-Refactors
Datenlayer sind kein Selbstzweck. Führungsteams wollen Kennzahlen sehen. Erste Leitgröße ist der Coverage Score, also der Anteil deiner Seiten mit validem Schema-Markup. Zweite Kennzahl ist die Retrieval Precision: Wie oft verwenden interne oder externe Modelle beim Prompt-Testing tatsächlich deine Entitäten? Dritte Zahl ist der Hallucination Drop, gemessen an manuellen QA-Prompts, die du regelmäßig gegen ChatGPT oder interne LLMs schickst. Ein Rückgang um fünfzehn Prozent innerhalb von drei Quartalen zeigt, dass deine Struktur ankommt. Vierte KPI ist die Conversion Assistance. Sie misst, wie viele Transaktionen durch Chat- oder Voice-Widgets initiiert wurden, die auf deinem Datenlayer laufen. Fünfte Metrik ist die Content Velocity. Wenn dein Team nach dem Refactor zwanzig Prozent weniger Zeit pro Seiten-Release benötigt, weil Templates Schema automatisch ausspielen, zahlt sich die Investition auch operativ aus. Lege diese Kennzahlen im OKR-Framework fest und berichte quartalsweise. Dann entwickelst du nicht nur besseren Content, sondern beweist auch, dass er Maschinen wirklich erreicht – und das überzeugt auch das letzte skeptische CFO-Ohr in der Vorstandsetage.
Ausblick für WordPress Agenturen: Vom Seitenbauer zum Datenarchitekten
Wer jetzt noch denkt, eine WordPress Agentur müsse bloß schicke Themes stapeln und ein paar Plugins konfigurieren, verkennt die neue Gewichtsklasse. In der Agentic-Ära avancieren wir vom Seitenbauer zum Datenarchitekten und zwar auf Vorstandsniveau. Unsere Kernaufgabe besteht nicht mehr darin, Slider einzubauen, sondern dafür zu sorgen, dass jede Entität auf einer Enterprise-Site Teil eines robusten Knowledge Graphs wird: Produkt-SKU, Autorenprofil, Standortcode, bis hin zu temporären Kampagnenrabatten. Das verlangt tiefe Expertise in WPGraphQL, ACF-Schemen und Deployment-Pipelines, aber ebenso in Data-Governance und Compliance. Denn was nützt das sauberste JSON-LD, wenn ein nachträgliches Preis-Update aus dem ERP nicht automatisiert durchgereicht wird? Genau hier spielt eine moderne WordPress Agentur ihre Stärken aus: Wir verknüpfen CMS, PIM und Shop-Backend zu einem einzigen Daten-Backbone, der für Menschen übersichtlich bleibt, zugleich aber jedem Agentic-System als verlässliche Quelle dient. Wer diesen Schritt geht, sichert sich nicht nur bessere SEO-Signale und niedrigere Halluzinationsraten, sondern auch einen handfesten Wettbewerbsvorteil: Während andere noch manuell Prompt-Pflaster kleben, liefern unsere Kunden bereits APIs, die LLMs blind vertrauen. Kurz: Eine WordPress Agentur, die Datenlayer denkt, wird vom Lieferanten einzelner Webseiten zum Integrationspartner, der Enterprise-Wertschöpfung und KI-Ökosystem in einem Atemzug orchestriert.
Bist du bereit, dir mit Syde einen Wettbewerbsvorteil zu verschaffen?
Ähnliche Artikel
-

The Thump: Was KI an WordPress niemals verstehen wird
Als Mumbai als Gastgeber für WordCamp Asia 2026 angekündigt wurde, schweiften meine Gedanken schnell vom Web ab – hin zu Motorrädern und zur Geschichte einer legendären Marke aus Indien. Ich
-

Warum die Wahl des richtigen CMS über Erfolg oder Misserfolg deiner Website entscheidet
Wenn es darum geht, eine Website zu erstellen, die wirklich für dein Unternehmen funktioniert, ist das CMS nicht einfach nur ein weiteres Tool – es ist das Rückgrat des gesamten Betriebs.