
In der Softwareentwicklung ist Git eigentlich nicht mehr wegzudenken. Mit Hilfe von Git können mehrere Entwicklerinnen an der gleichen Codebasis arbeiten, ohne in Gefahr zu geraten, sich gegenseitig den Code zu überschreiben. Git ist ein Versionskontrollsystem, das ermöglicht, bequem durch die Codehistorie zu surfen. Notfalls kann auch auf einen bestimmten Zeitpunkt zurückgesetzt werden. Und nicht zuletzt kann man mit Hilfe von Branches an verschiedenen Themen gleichzeitig arbeiten.
All diese Features haben Git zu einem unverzichtbaren Tool in der professionellen Softwareentwicklung gemacht. Zugleich ist es aber auch ein komplexes Werkzeug. Doch kennt man erst einmal ein wenig die grundlegende Funktionsweise, wird auch die Handhabung dieses Werkzeuges einfacher.
Während des Wordcamps Stuttgart 2019 habe ich deshalb einen Talk zu dem Thema “Understanding Git. What it going on in .git/?” gehalten. Hier erkläre ich was eigentlich im .git/-Verzeichnis von statten geht, während Dateien unter Versionskontrolle gestellt werden und neue Commits erzeugt werden.
Im ersten Teil des Vortrags stelle ich also das grundlegende Datenkonzept vor, mit dem Git seine Versionskontrolle erzeugt. Im zweiten widme ich mich dem gefürchteten git reset --hard und zeige, wie wir – jetzt mit einem besseren Verständnis der zugrunde liegenden Datenstruktur – Code wieder zurückholen können, den wir eigentlich verloren glaubten.
Was passiert eigentlich im .git-Verzeichnis? Die Datenstruktur von Git
Die zwei wesentlichen Kommandos von Git sind git add und git commit. Mit Hilfe dieser beiden Befehle werden die Commits angelegt. Aber wo und in welcher Form werden diese Informationen eigentlich gespeichert?
Jedes Git Repository besitzt ein Verzeichnis mit dem Namen .git/.
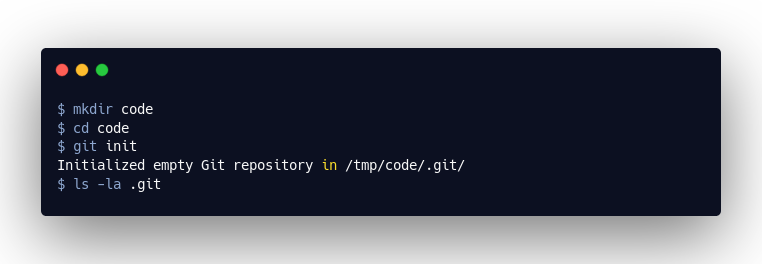
Erstellen wir einen ersten Commit
Wie wir sehen, finden sich in diesem Verzeichnis mehrere Dateien und Verzeichnisse. Die von uns erstellten Commits werden in .git/objects/ als sogenannte Objekte hinterlegt.
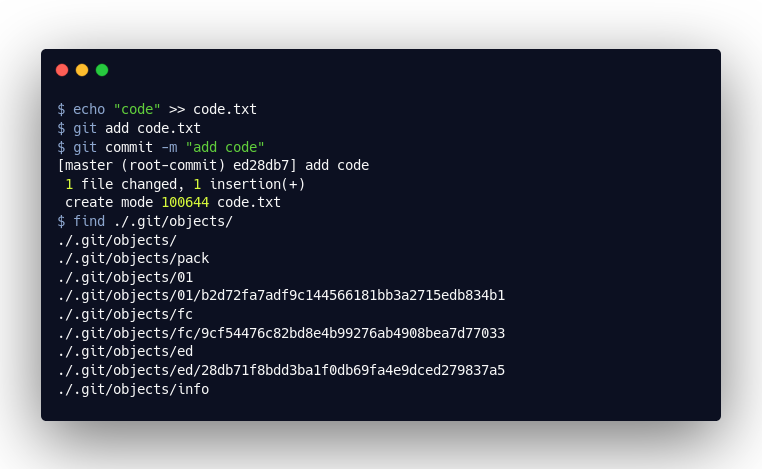
Wie wir sehen, wurden durch unsere Aktion drei Objekte angelegt. Mit Hilfe von git cat-file können wir diese Objekte öffnen und deren Inhalt einsehen.
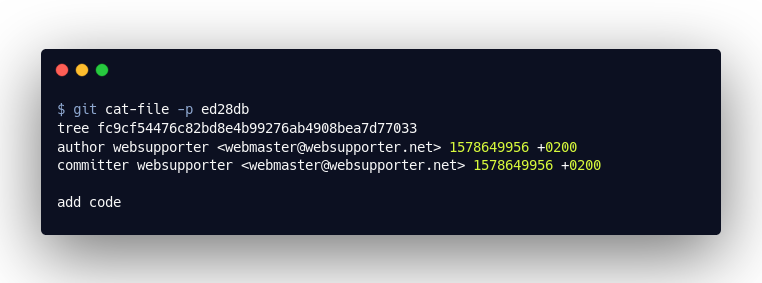
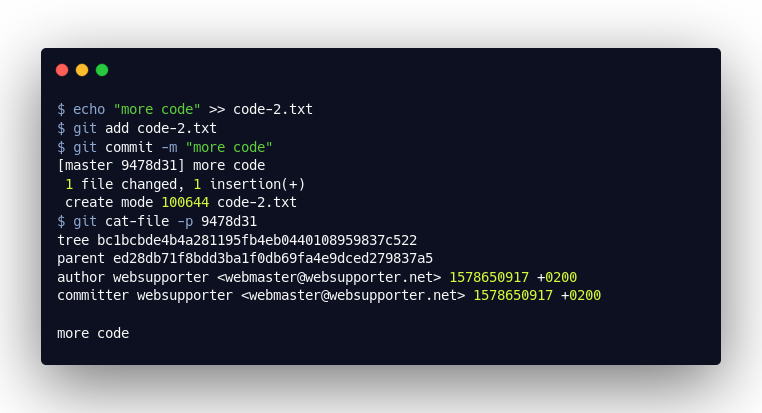
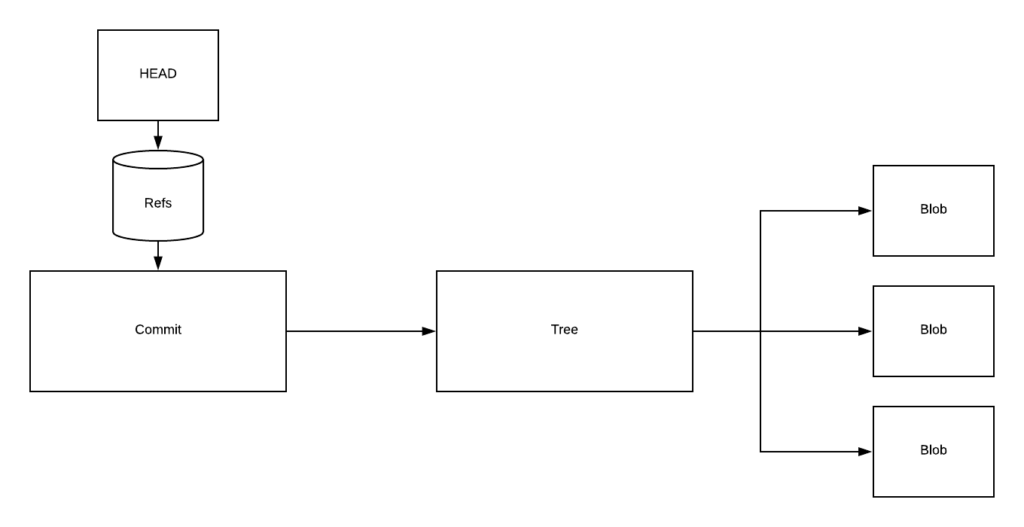
Das erste Objekt, das wir öffnen ist das ed28db7. Hierbei handelt es sich um das “Commit”-Objekt, welches mit git commit erstellt wurde. Dieses enthält alle Informationen zu dem Commit: also die Autoren, die Commitnachricht sowie einen Verweis auf das sogenannte “Tree”-Objekt. Sobald wir einen zweiten Commit erstellen, wird dieses Objekt auch die Information enthalten, welcher Commit der vorangegangene Commit (parent) war ‒ womit wir dann eine Historie erhalten. Doch sehen wir uns zunächst das “Tree”-Objekt an:
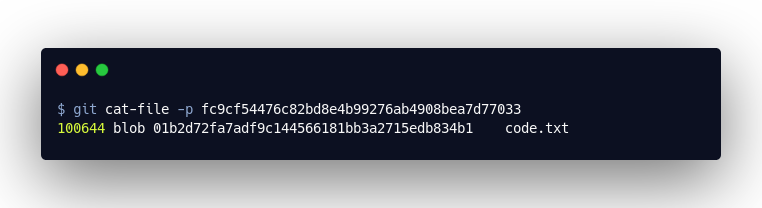
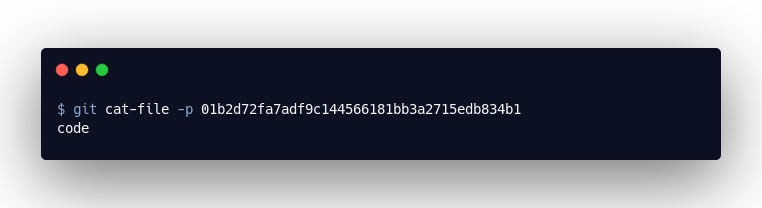
Dieses Objekt ist eine Liste. Sie verweist auf die sogenannten “Blob”-Objekte. In diesen sind die Inhalte der Dateien gespeichert, welche wir committed haben. Letztlich gibt uns das “Tree”-Objekt also Auskunft darüber, wo wir die Inhalte von unserer code.txt finden, nämlich in 01b2d72fa7adf9c144566181bb3a2715edb834b1:
Woher kommen die Dateinamen der Objekte?
Die Dateinamen sind ein Hashwert des Dateiinhalts. Unsere code.txt enthielt den Text “code”. Der Hashwert dieses Strings ist “01b2d72fa7adf9c144566181bb3a2715edb834b1”. Der Hashwert von 100644 blob 01b2d72fa7adf9c144566181bb3a2715edb834b1 code.txt dagegen ist „fc9cf54476c82bd8e4b99276ab4908bea7d77033“.
Erstellen wir einen zweiten Commit
Sehen wir uns nun an, was passiert, wenn wir einen zweiten Commit erstellen. Das neue “Commit”-Objekt enthält nun eben auch den Verweis auf den vorangegangenen Commit:
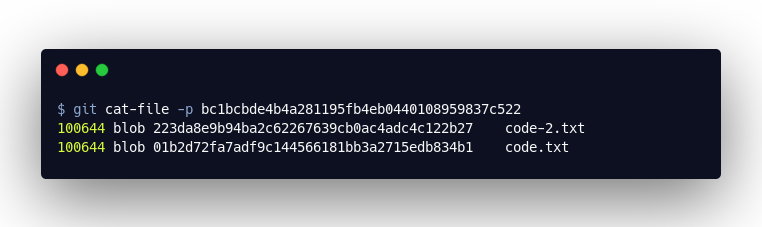
Das neue “Tree”-Objekt enthält nun zwei Einträge. Wir sehen zum einen unsere neue Datei code-2.txt, daneben aber noch immer die Referenz zu unserer code.txt. Das “Tree”-Objekt verweist also auf den kompletten Code zum Zeitpunkt des Commits.
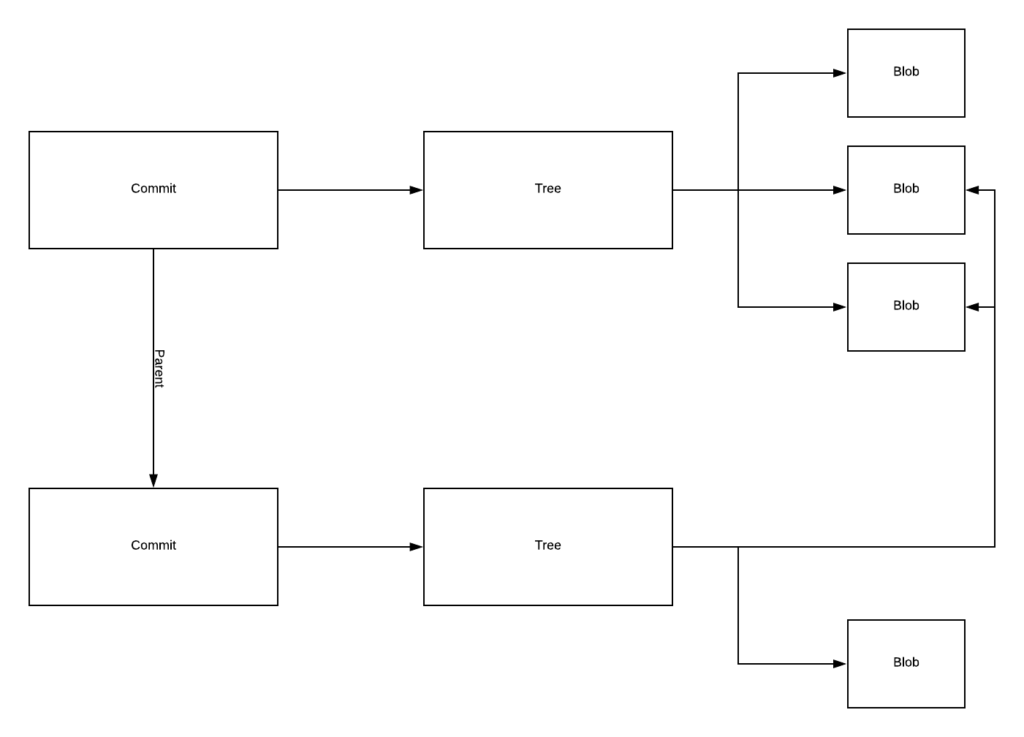
Damit haben wir das zentrale Datenmodell von Git herausgearbeitet:
Was sind Branches in Git?
Mit git checkout {branch-name} kann man zwischen Branches wechseln und mit git checkout -b {branch-name} kann man neue Branches erstellen. Der nächste Teil meines Vortrags beschäftigte sich damit, wie diese Informationen im .git/-Verzeichnis hinterlegt werden. Branches sind dabei nichts weiter als Textdateien, die auf ein „Commit“-Objekt referenzieren. Diese finden sich unter .git/refs/heads/. Auch Tags sind nichts anderes und finden sich in .git/refs/tags/.
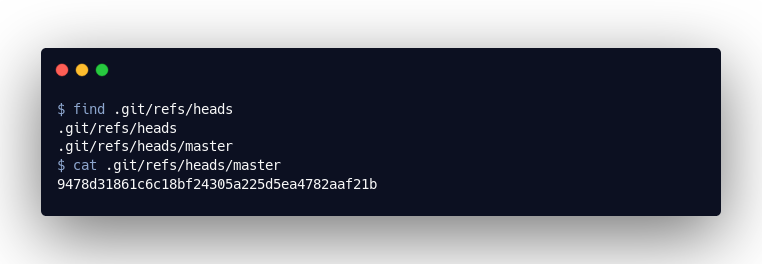
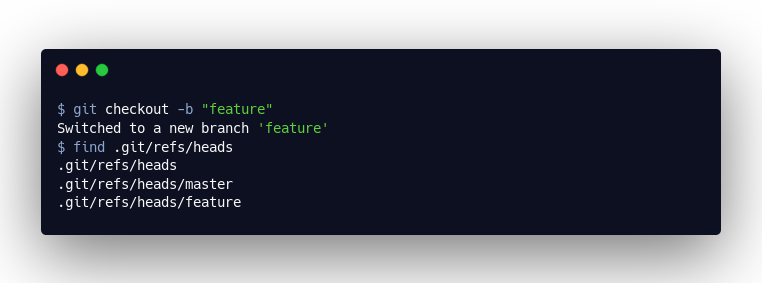
Öffnen wir also die master-Datei, so sehen wir hier einfach eine Referenz auf unseren letzten Commit „9478d31861c6c18bf24305a225d5ea4782aaf21b“. Erstelle ich nun einen neuen Commit in diesem Branch, wird diemaster-Datei entsprechend aktualisiert und, wenn wir einen neuen Branch erstellen, so legen wir nur eine neue Datei in .git/refs/heads mit einem Verweis auf das aktuelle „Commit“-Objekt an:
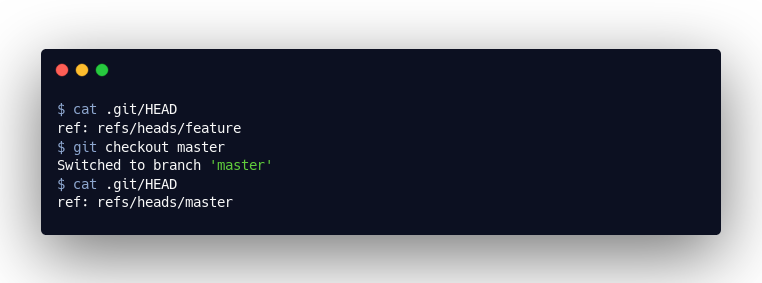
So bleibt zum Schluss nur noch die Frage, wo wir uns eigentlich aktuell befinden: die Frage nach unserem HEAD. Und auch hierbei handelt es sich einfach um eine Textdatei, welche (normalerweise) auf die Branch-Datei verweist
Über diese Referenzierungen erhalten wir also folgende Struktur:
Git Anwendungsbeispiel
Mit Hilfe dieses neuen Verständnisses der grundlegenden Datenstruktur von Git können wir nun ein besseres Verständnis dafür entwickeln, was einzelne Git-Befehle eigentlich tatsächlich machen. In meinem Vortrag arbeite ich deshalb am Beispiel der fiktiven Themeschmiede “TipTopThemes” die Funktionsweise von git reset --hard heraus. Gerade, wenn man mit Git erst beginnt, ist dieser Befehl durchaus gefürchtet. Die Angst: Macht man etwas falsch, dann ist der eigene Code plötzlich unwiderruflich weg.
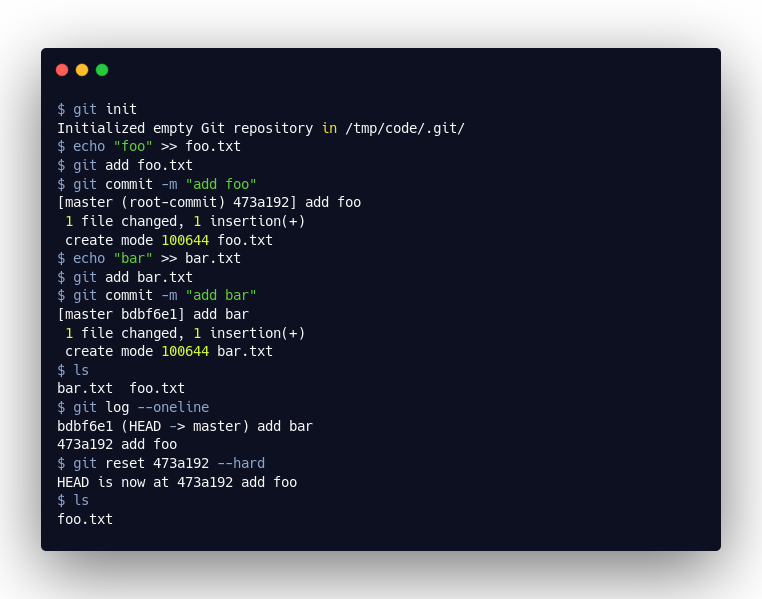
Nehmen wir das obige Beispiel. Wie wir sehen hat git reset --hard tatsächlich die bar.txt aus unserem Arbeitsbereich gelöscht. Wenn wir uns die aktuelle master-Referenz anschauen, sehen wir auch, dass sich diese geändert hat:
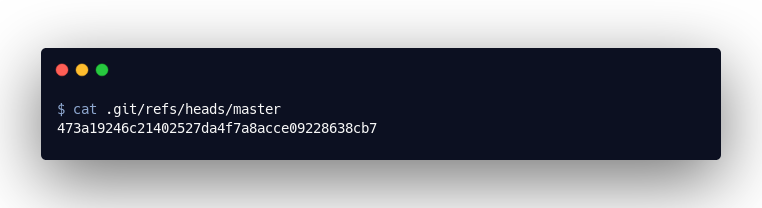
Doch interessant ist nun die Ausgabe des folgenden Befehls:
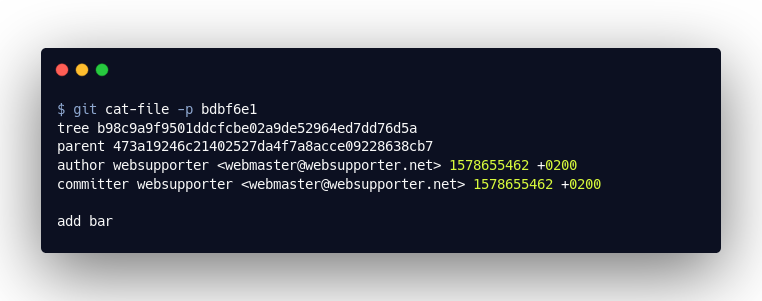
Obwohl wir resettet haben können wir nach wie vor das “Commit”-Objekt einsehen, mit dem wir die bar.txt hinzugefügt hatten. Auch das „Tree“- und das „Blob“-Objekt der bar.txt wurden durch git reset nicht gelöscht! Das heißt unser Code ist nach wie vor in diesem Universum von Objekten vorhanden!
Git reflog is your friend
Wenn man nur irgendwie sinnvoll an den entsprechenden Commit käme! Keiner merkt sich doch diese Hashwerte. Doch; git reflog:
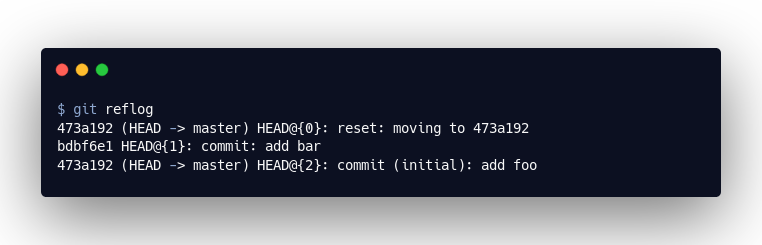
Git erstellt im .git/logs-Verzeichnis Log-Dateien, die nachvollziehen, wie sich der HEAD über den Zeitraum der letzten 90 Tage bewegt hat. Hier sehen wir nun, dass wir zunächst auf dem Commit 473a192, dann auf bdbf6e1 und schließlich wieder auf 473a192 waren.
Da wir nun unseren Commit mit den verloren gegangenen Code kennen, können wir ganz einfach, beispielsweise mit git reset bdbf6e1 --hard den Code wiederherstellen und weiterarbeiten.
Allerdings sollte einem klar sein, dass Git über einen internen Garbage Collector verfügt. Dieser beschneidet die Log-Dateien, damit sie nicht endlos groß werden und löscht auch verwaiste Objekte nach zwei Wochen. Mit git reset 473a192 --hard verwaiste der Commit bdbf6e1. Wenn wir diesen nicht rechtzeitig wieder in irgendeine Branch-Kette bringen oder ihn taggen, so wird dieser Commit, sein Tree und Blobs, die nicht mehr in anderen Trees referenziert werden, gelöscht.
Danke
Am Ende nochmal vielen Dank an die Organisatorinnen und Organisatoren und die Freiwilligen des WordCamps Stuttgart. Es war ein wirklich angenehmes Wochenende mit vielen interessanten Gesprächen und Vorträgen in einer tollen Location.
Failed to submit:
one or more fields are invalid.