
When it comes to software development, it’s hard to imagine a world without Git. Multiple developers can use Git to work on the same code base at the same time, without any danger of overwriting each other’s code. Git is a version control system that allows you to easily browse through the code history. If necessary, the code can also be reverted to a specific point in time. Last but not least, the use of branches allows that various topics can be worked on at the same time.
All these features have made Git an indispensable tool in professional software development. It is, however, a complex tool. But once you know a little about the basic functions, handling this tool becomes much more simple.
At Wordcamps Stuttgart 2019, I therefore held a talk on the topic of “Understanding Git. What is going on in .git/?” Here I will explain what actually happens in a .git/ directory when files are put in version control and new commits are created.
In the first part of the presentation, I introduce the basic data concept that Git uses to create its version control. In the second part, I look at the dreaded git reset --hard and show how, with an improved understanding of the underlying data structure, we can recover code that we thought was lost forever.
What Actually Happens in a .git Directory? The Data Structure of Git
The two most important Git commands are ultimately git add and git commit. These two commands are used to create commits. But where and in what form is this information actually stored?
Each Git repository has a directory named .git/.
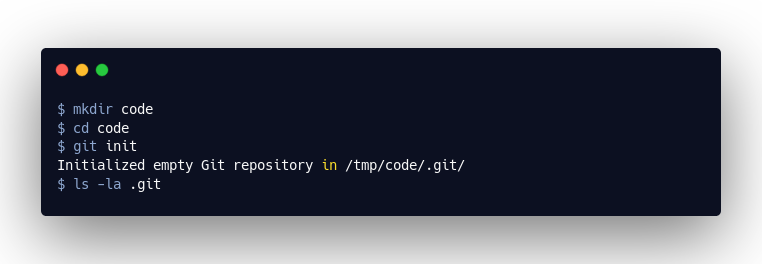
Let’s Create Our First Commit
As we can see, there are several files and directories in this directory. The commits we create are stored in .git/objects/ as “objects”.
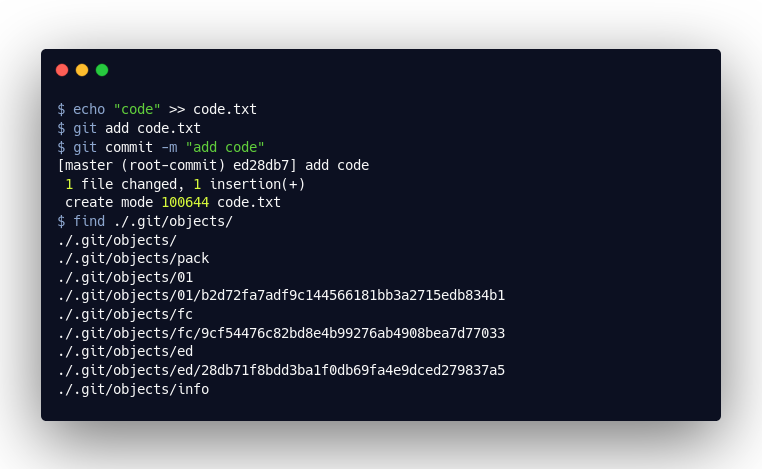
Here we see that our action created three objects. By using the git cat-file, we can open these objects and view their content.
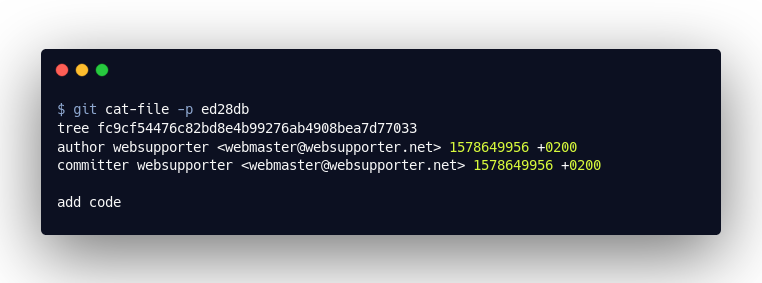
The first object we open is ed28db7. This is the “commit” object that was created with git commit. It contains all the information on the commit: the authors, the commit message and a reference to the so-called “tree” object. As soon as we create a second commit, the object will also specify the previous commit (parent), providing us with a history. But let us first look at the “tree” object:
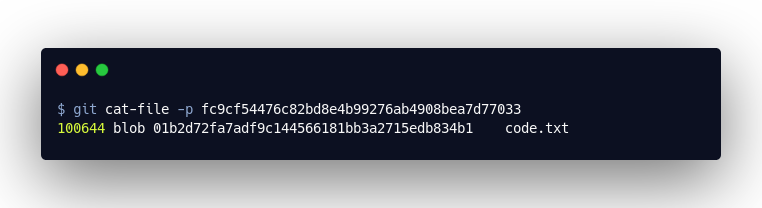
This object is a list. It refers to the so-called “blob” objects. These contain the contents of the files we have committed. Ultimately, the “tree” object tells us where to find the content of our code.txt, namely in01b2d72fa7adf9c144566181bb3a2715edb834b1:
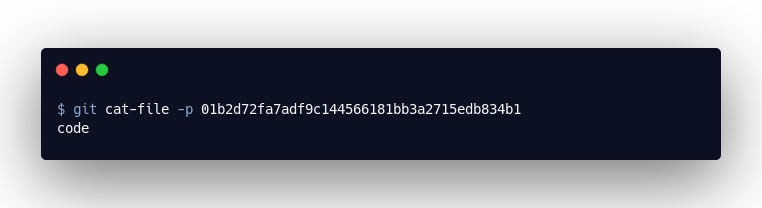
Where Do the File Names of the Objects Come From?
The file names are a hash value of the file content. Our code.txt contains the text “code.” The hash value of this string is “01b2d72fa7adf9c144566181bb3a2715edb834b1”. The hash value of 100644 blob 01b2d72fa7adf9c144566181bb3a2715edb834b1 code.txt on the other hand, is “fc9cf54476c82bd8e4b99276ab4908bea7d77033”.
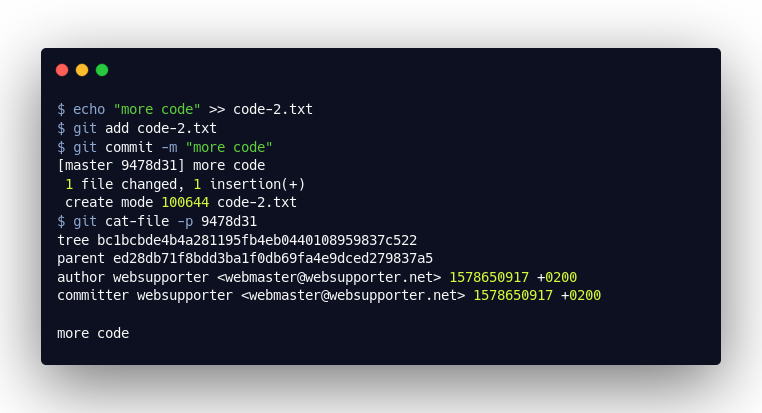
Let’s Create a Second Commit
Now let’s look at what happens when we create a second commit. The new “commit” object contains a reference to the previous commit:
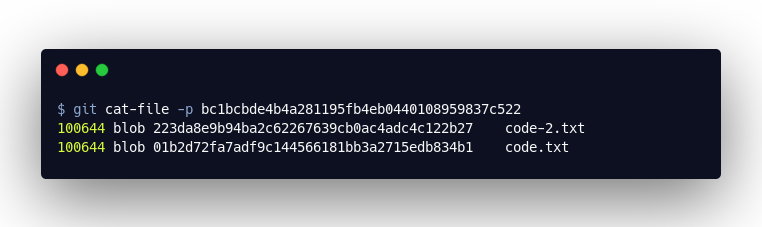
The new “tree” object contains two entries. We see our new file code-2.txt, but next to it we still see the reference to our code-2.txt. The “tree” object therefore refers to the complete code at the time of the commit.
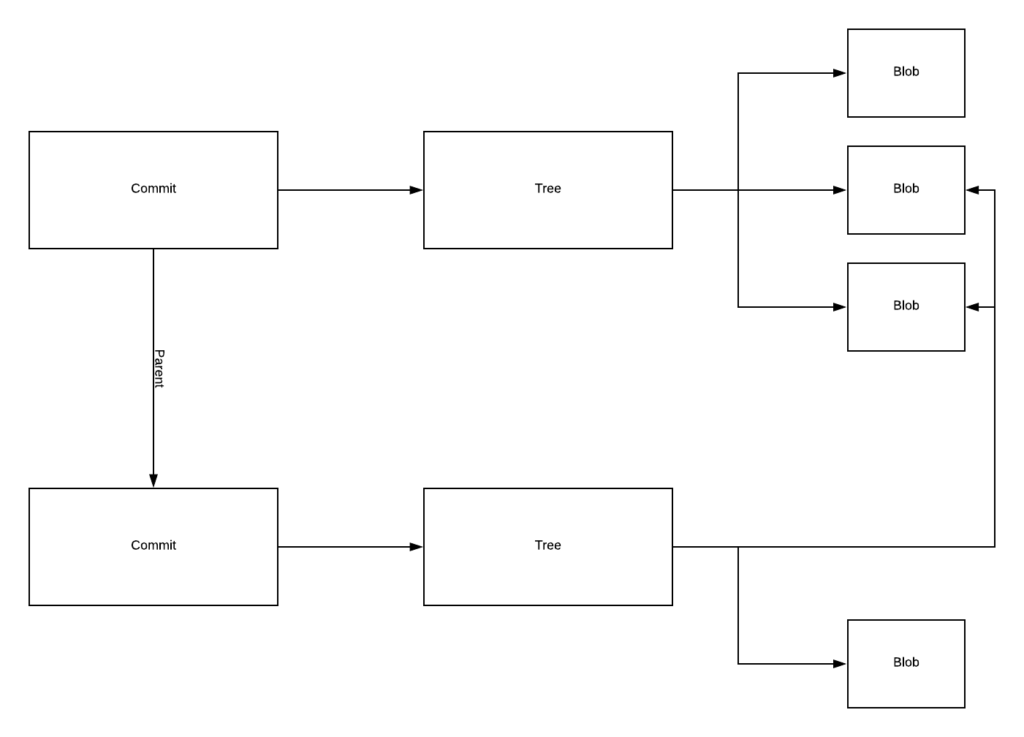
And just like that, we’ve worked out the central data model for Git:
What Are Branches in Git?
You can switch between branches with git checkout {branch-name}, and you can create new branches with git checkout -b {branch-name}. The next part of my talk was about how this information is stored in the .git/ directory. Branches are nothing more than text files that reference a “commit” object. These can be found under .git/refs/heads/. Tags are also nothing more than that, and can be found in .git/refs/tags/.
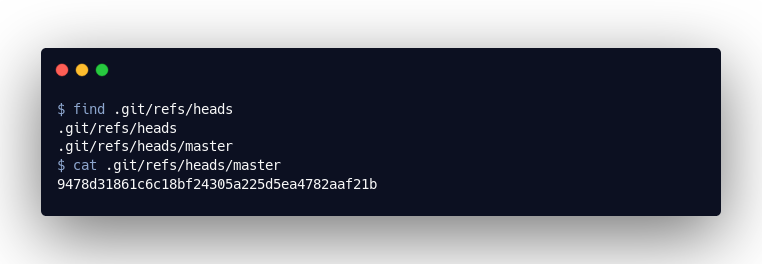
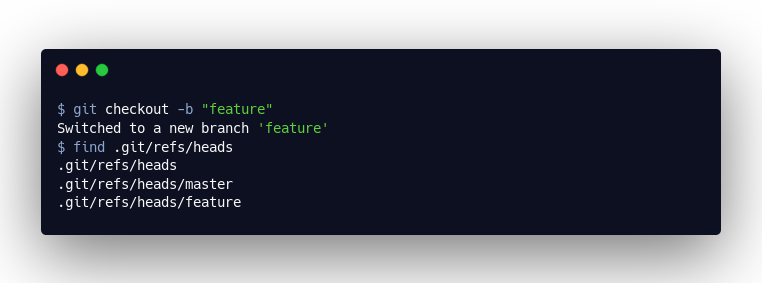
When we open the master file, we simply see a reference to our last commit “9478d31861c6c18bf24305a225d5ea4782aaf21b”. If I now create a new commit in this branch, the master file is updated accordingly, and, if we create a new branch, we just create a new file in .git/refs/heads with a reference to the current “commit” object:
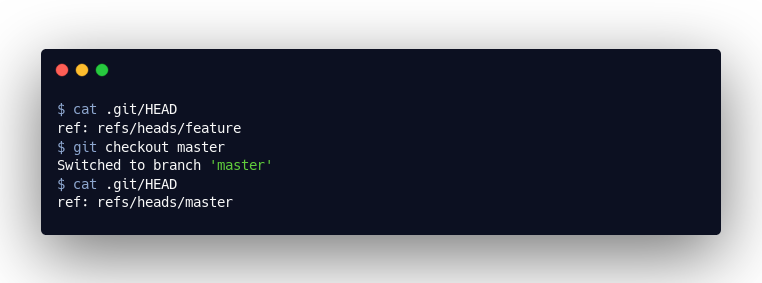
The only question that remains is that of the HEAD, i.e. where we currently find ourselves. This is also simply a text file, which (generally) refers to the branch file:
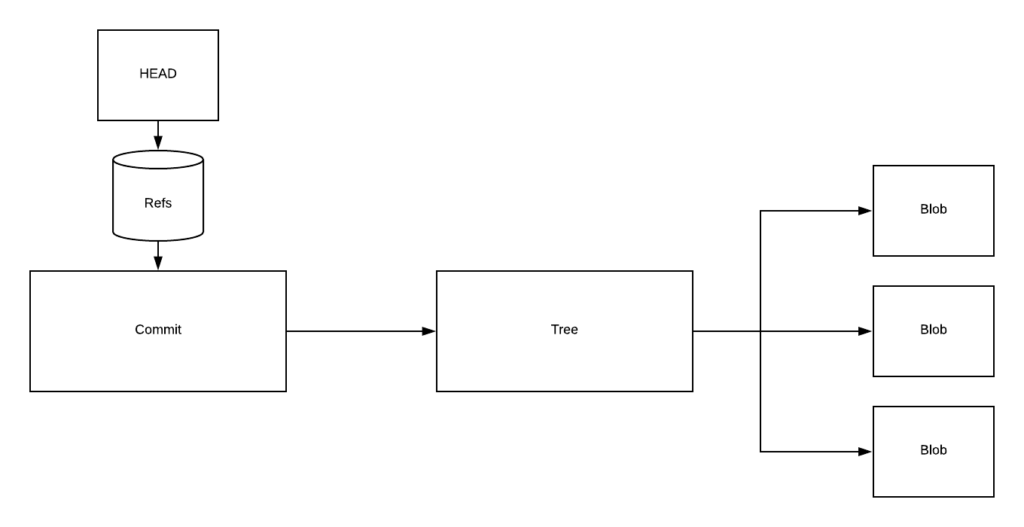
These references provide us with the following structure:
Git Application Example
With the help of this new understanding of the underlying data structure of Git, we can now develop a better understanding of what individual Git commands actually do. In my presentation, I therefore use the fictional theme developer “TipTopThemes” as an example to show how git reset --hard works. This can be a dreaded command, especially when you’re just starting out with Git. The common fear is that you’ll do something wrong and your code will suddenly be permanently lost.
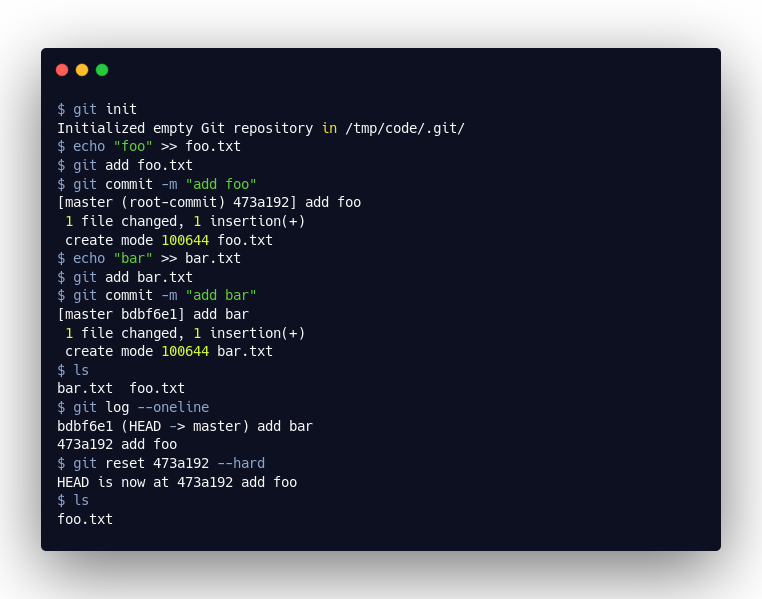
Let’s take the example above. As we can see, git reset --hard did indeed delete the bar.txt from our work area. If we look at the current master reference, we can see that this was also changed:
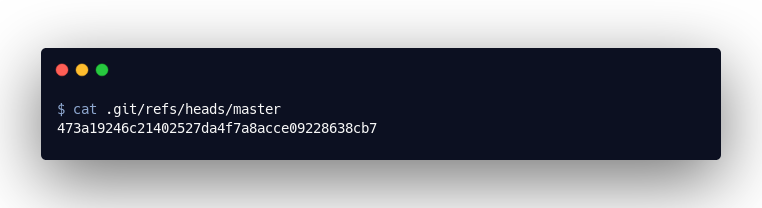
But the output of the following command is now of interest:
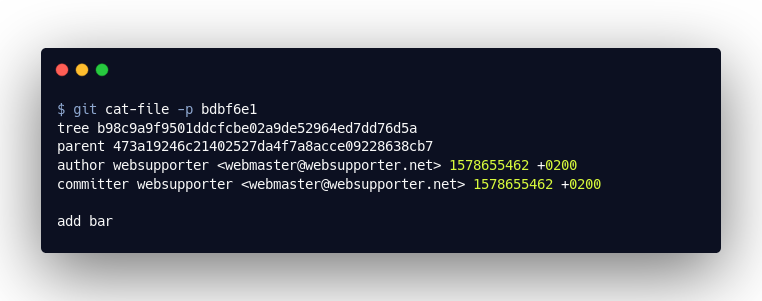
Despite the fact that we reset, we can still see the “commit” object that we used to add the bar.txt. The “tree” and “blob” objects of the bar.txt were also not deleted by the git reset! This means that our code is still out there in the “universe” of objects!
Git reflog is your friend
If only there were some way to get to the corresponding commit! Surely nobody remembers the hash value. git reflog does!
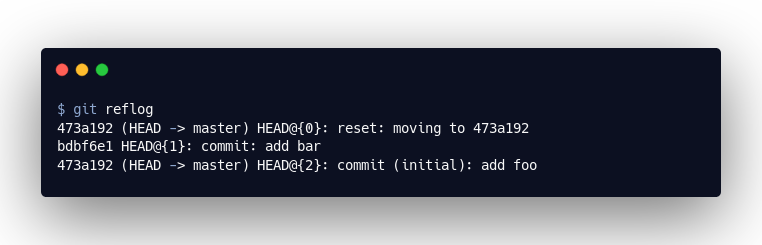
Git creates log files in the .git/logs directory that track how the HEAD has moved over the last 90 days. Here we can see that we were initially at commit 473a192, then bdbf6e1 and finally back at 473a192.
Now we know the commit with the missing code, we can easily use git reset bdbf6e1 --hard, for example, to restore the code and continue working.
However, you should be aware that Git has an internal garbage collector. This truncates log files so that they don’t become endlessly long, and also deletes orphaned objects after two weeks. With git reset 473a192 --hard, the commit orphaned bdbf6e1. If we don’t get this back into a branch chain or tag it in time, this commit, as well as its tree and blobs that are no longer referenced in other trees, will be deleted.
Thank you
Finally, I would like to thank the organizers and volunteers of WordCamp Stuttgart. It was a thoroughly enjoyable weekend with lots of interesting discussions and presentations in a great location.
Failed to submit:
one or more fields are invalid.