
Machine Learning algorithms are widely used nowadays in applications such as recommendation systems (like Amazon or Netflix), fraud detection, cancer prediction and many more. But what exactly is Machine Learning and how does it work?
The Definition: Machine Learning is a method of data analysis that provides computers the ability to automatically find hidden patterns in the data, without being explicitly programmed.
In this article, we are going to introduce you to Machine Learning developing a Linear Regression model. To do so, we are going to use the PHP-ML library which implements regression algorithms like Least Squares used in this article.
In order to follow the code examples in this article, I created a repository in GitHub.
Linear Regression
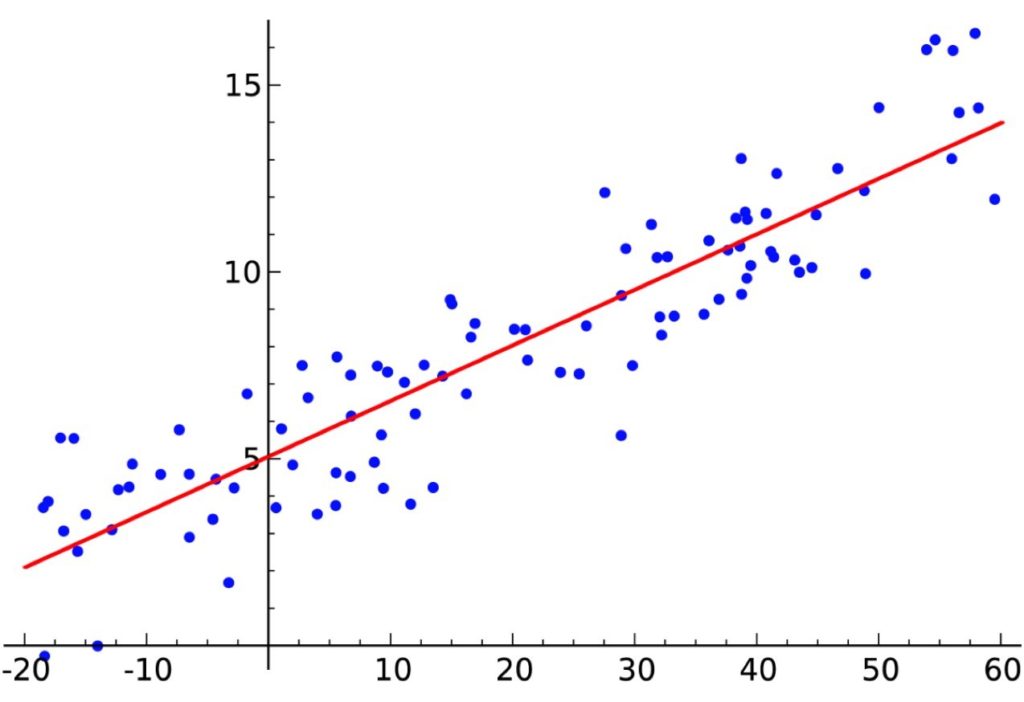
Linear regression assumes a linear relationship between input (X) and output (y) variables, so the output (y) can be calculated from a linear combination of the input variables (X). When there is a single input (X), the algorithm considers a two-dimensional sample and is referred to as a Simple Linear Regression.
Load Data
To start developing our Machine Learning model, we’ll need to load some data. In this article, we are going to use sample data from Kaggle related to advertising. In this sample, the inputs (X) are the money spent on each channel (TV, Radio…) and the output (y) is the total sales. We are going to create a model that will allow us to predict how many sales we’ll have based on the money spent on advertising.
I’ve created a sample data with only one input (X). At the end of the article, we’ll see how we can add more inputs to improve the efficiency of our model.
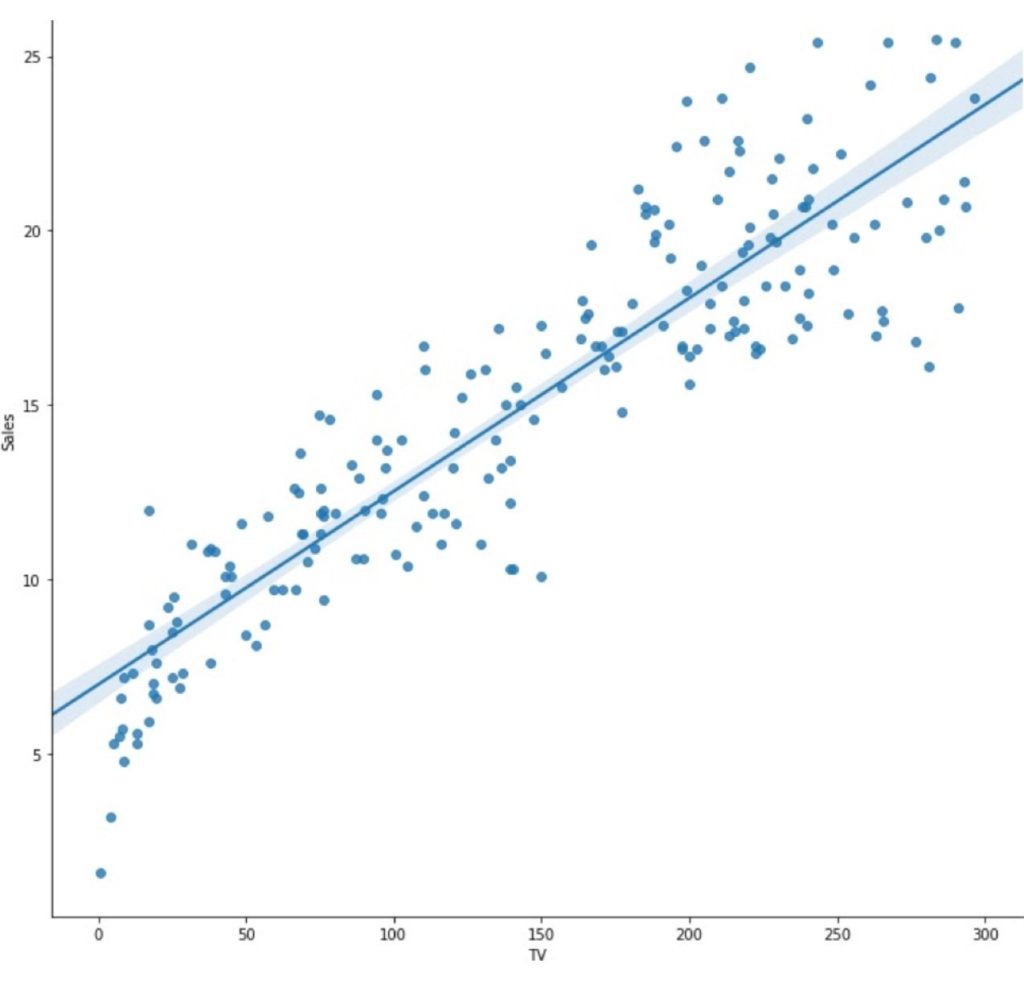
As you can see in the above graph, if we plot the values of TV on X-axis and Sales on Y, we can clearly see a linear pattern. It shows that the more money invested in TV advertising, the more the sales will grow.
So let’s start loading our data. To do so, we use CsvDataset class:
$dataset = new CsvDataset('dataset.csv', 2, true);The first parameter is the file path, the second is the number of inputs (X) in the file and the third is to specify that the file contains a header in the first line. The third parameter is optional and set to “true” by default.
Train and Test Data Split
The next step is splitting the data into two groups. One group will be used to train the model and the other for testing. It is important to note that, when we test the model, the data has to be never seen before. Otherwise, the results will be inaccurate because the model already knows these output values from the training data.
To split the data, we can use RandomSplit-class like this:
$randomSplit = new RandomSplit($dataset, 0.3, 1234);The first parameter is the dataset, the second the range of the split. In this case, 70% for training and 30% for testing. The third parameter is an arbitrary number that we can reuse to ensure the same random result.
Train the model
After data is splitted into two parts (train and test), we are going to train the model by using train data. To do so, we use the train method from LeastSquares Linear Regression class like this:
$regression = new LeastSquares();
$regression->train(
$randomSplit->getTrainSamples(),
$randomSplit->getTrainLabels()
);The first parameter is the input (X) and the second is the output (y).
Model evaluation metric
Now that we have our model trained, it is time to find out how good (or bad) our model is. To do so we need some kind of metric. This is where the error metrics come into play. So, once we have the value of the error metric, we can work on our model improving it based on that error value. The lower the value, the better our model will be.
In this article, we are going to use Mean Absolute Error (MAE) which provides the error in the predicted values in comparison to the expected values. PHP-ML latest version provides a handy meanAbsoluteError method in Regression class that we are going to use like this:
$error = Regression::meanAbsoluteError(
$randomSplit->getTestLabels(),
$regression->predict($randomSplit->getTestSamples())
);The first parameter is the expected output (y) from our test data (remember, this data has to be never seen before by the trained model), the second parameter is the predictions from our trained model. The result value will be the average of how close (or far) those two parameters are.
Improve the model
There are many techniques to improve the model. In our case, we are going to simply add more inputs. As you may remember from the beginning of the article, we loaded a sample data with only one input (X). After the model was trained, the Mean Absolute Error (MAE) was about 1.8. After that, I loaded this sample with 3 inputs and trained the model again. The MAE, in this case, was around 1.2, which is better than the previous one.
Model Persistency
As a final step, we can persist our trained model. In this way, we can reuse it at any time in the future without having to train the model over and over again.
PHP-ML provides a ModelManager class that we can use to store the model:
$modelManager = new ModelManager();
$modelManager->saveToFile($regression, 'trained-model.dat');And to load the model:
$model = $modelManager->restoreFromFile('trained-model.dat');Putting it all together
I have created a couple of console commands that you can run in you terminal:
php bin/console train data/advertising.csv 3The first parameter is the file and the second the number of inputs (X). It returns the MAE value after training and storing the model.
php bin/console predict 10,20,30The parameter is a comma-separated value with the 3 inputs (TV, Radio, and Newspaper). It returns the sales prediction for these inputs.
Conclusion
We now know what Machine Learning is and how to use a simple Machine Learning algorithm such as Simple Linear Regression. The process may vary depending on the type of Machine Learning model, but at its core is usually the same as described in this article. First, you get the data, then you create and train the model based on that data and finally you deploy that model to use it. In real applications, models are continuously retrained and improved as new data arrives into the system.
Failed to submit:
one or more fields are invalid.